
Datenschutz (I) - Missverständnisse
 Wenn ich mit Leuten spreche, die nicht so internet-, daten-, computer- oder technikaffin sind, stelle ich immer wieder fest, dass sich in Bezug auf Datenschutz riesige Klüfte auftun, vor allem im gegenseitigen Verständnis. Dies wird klar, wenn (wie immer irgendwann) der Satz fällt: "Ich habe nichts zu verbergen". Eine naheliegende Reaktion ist es ihnen eine Liste, wie diese von Frau B. "Nichts zu verbergen", entgegenzuhalten. So eine Liste offenbart aber nur die Kluft, die dazwischen liegt, und ist nur begrenzt förderlich für die Diskussion. Warum? Dazu sollte man sich die beiden Seiten etwas genauer betrachten.
Wenn ich mit Leuten spreche, die nicht so internet-, daten-, computer- oder technikaffin sind, stelle ich immer wieder fest, dass sich in Bezug auf Datenschutz riesige Klüfte auftun, vor allem im gegenseitigen Verständnis. Dies wird klar, wenn (wie immer irgendwann) der Satz fällt: "Ich habe nichts zu verbergen". Eine naheliegende Reaktion ist es ihnen eine Liste, wie diese von Frau B. "Nichts zu verbergen", entgegenzuhalten. So eine Liste offenbart aber nur die Kluft, die dazwischen liegt, und ist nur begrenzt förderlich für die Diskussion. Warum? Dazu sollte man sich die beiden Seiten etwas genauer betrachten.
Die "nichts zu verbergen"-Leute
Für die "nichts zu verbergen"-Leute ist solch eine Liste kein Widerspruch. Was wir Geeks (oder wie auch immer man das nennen mag) vom eher idealistisch-kritischen Ansatz her vergessen ist, dass Datenschutz für die normalen Menschen sehr viel mit Vertrauen und Wahrnehmung zu tun hat.
Wahrnehmung ist für sie gleichbedeutend mit Realität und das ist jemand,
- der durch das Fenster glotzt
- der ihnen auf die Terrasse glotzt
- der sie in der öffentlichen Dusche anglotzt
- der ihr Tagebuch liest
- der, ganz generell, in privaten Dingen stöbert
- der ihnen am Bankautomaten über die Schulter sieht
prinzipiell also jemand der ihr unmittelbares Gefühl von sozialem Abstand und Privatsphäre verletzt.
Begründet liegt dies im Vertrauen zu und Umgang mit anderen Menschen:
- was denken Menschen von mir, mit denen ich tagtäglich zu tun habe
- ich will nicht, dass über mich getratscht wird
- ich will Einbrechern keinen Anreiz bieten
- ich will mich nicht lächerlich machen
- ich will nicht ausgeraubt werden oder mein Konto geplündert haben
Bei all diesen Dingen besteht eine direkte, völlig unabstrakte Verbindung in der Wahrnehmung.
Dazu kommt, dass bei vielen "der Staat" als prinzipiell gut eingestuft wird (was ja eine korrekte Annahme sein soll(te)). Der Staat schützt die Bürger und die Bürger leisten einen Beitrag zum Staat, und damit es für alle gerecht zugeht, muss der Staat eben ein bisschen genauer hinsehen dürfen.
Soweit geht auch die Aussage "Ich habe nichts zu verbergen" in Richtung Staat gedacht voll in Ordnung. Oft übertragen sie diese Art von Vertrauen auch auf andere, als (historisch) seriös eingestufte Institutionen wie Banken, Versicherungen, Telefongesellschaften, Verkehrsunternehmen, ... Leider hat sich in den letzten Jahren durch Privatisierung und Konkurrenzunternehmen und damit Preisdruck vieles verändert, so dass dieses Vertrauen nicht mehr immer gerechtfertigt ist.
Der Schutz ihrer Daten ist für sie jedoch eine recht abstrakte Sache, dessen Absenz sie momentan hauptsächlich dadurch wahrnehmen, dass ihr Briefkasten mit Werbung zugeschüttet wird, oder sie sich über Telefonspammer ärgern müssen.
Die "Geeks"
Die Geeks (ich behalte diesen Terminus einfach bei) funktionieren anders. Für die meisten gibt es eine recht einfache und klare Sicht der Dinge:
- Die Wahrnehmung macht keinen Unterschied. Daten sind Daten und sind abstrakt zu betrachten
- Vertrauen gibt es nicht als Vorschuss; es muss verdient sein, ist aber trotzdem ständig weiterhin zu hinterfragen
Dies gilt erst einmal für alles und jeden und damit (gerade) auch für den Staat, der am meisten sammelt und am tiefsten in in das Grundrecht auf informationelle Selbstbestimmung eingreift. Damit wird klar, wo die Gegensätze liegen.
Annäherung
Dieses Missverständnis ist aber nur auf den ersten Blick wirklich eines und es dient der Annäherung, wenn man den Datenschutz auf einen eher technischen Standpunkt abstrahiert, denn eine Diskussion über Wahrnehmung und Vertrauen wird immer zum Scheitern verurteilt sein.
Das Wort Datenschutz enthält eine ganz wichtige Aussage: den Schutz der Daten. Damit steht und fällt alles und das ist keine Frage der Wahrnehmung oder des Vertrauens, hier zählen Fakten.
Die Fakten sind aber nun mal:
Wir sind von einem effektiven Schutz der Daten weit entfernt. Sowohl technisch als auch organisatorisch kenne ich kein Unternehmen oder keine Organisation - auch nicht den Staat - die einen 100%igen Schutz der Daten gewährleisten können. Der Datenschutz ist auch dann relevant, wenn man von einer absoluten Vertrauenbasis ausgeht. Es gibt genügend Beispiele dafür, dass der Schutz der Daten nicht funktioniert hat, obwohl kein Missbrauch beabsichtigt war, sondern "nur" technische oder organisatorische Gründe dazu geführt haben. Ein aktuelles, anschauliches Beispiel ist der "Fall Libri", aufgedeckt von netzpolitik.org. Siehe hierzu die Artikel "Exklusiv: Die Bücher der Anderen" und "Exklusiv: Die Libri-Shops der Anderen" auch bei heise.de zu lesen " Libri lässt Kundenrechnungen offen im Netz liegen" und " Datenleck bei Libri zieht weitere Kreise".
Dem Datenschutz stehen immer wirtschaftliche Interessen entgegen, sowohl von Einzelpersonen als auch von Unternehmen. Profildaten per se sind wertvoll. Aufgaben lassen sich (kostengünstiger) von Drittanbietern erbringen, dafür müssen die Daten weitergegeben werden. Im Falle eines Dienstleisters für Postaussendungen muss dieser Adressdaten haben. Alleine diese sind für andere Unternehmen der gleichen Branche schon wertvoll, z.B. für eine Kundenakquise. Ein kleines "Kavaliersdelikt" und schon wechselt eine Kopie der Adreßdaten den Besitzer, erstellt durch einen Mitarbeiter des Dienstleisters für eine finanzielle Anerkennung.
Dass eine derartige Weitergabe der Daten wirklich passiert, auch bei grossen Unternehmen wie der Postbank, zeigt das Ergebnis einer aktuellen Untersuchung der Stiftung Warentest: "Datenmissbrauch bei der Postbank:Systematische Verstöße gegen den Datenschutz".Direkter Mißbrauch der Daten durch Zweckentfremdung. Ein anschauliches Beispiel hierfür ist die hart geführte Diskussion um die Daten von Toll Collect. Sollen Daten, die nur für die Verkehrauskommensabrechnung erhoben wurden, dafür genutzt werden, um Ermittlung und Strafverfolgung zu ermöglichen. Im Mautgesetz (PDF via juris.de) wurde explizit eine Zweckbindung des Systems auf die Mauterhebung festgelegt, damit eben gerade keine Bewegungsprofile und Rasterfahndungen erstellt und durchgeführt werden können:
§ 7 Kontrolle (2)
Diese Daten dürfen ausschließlich zum Zweck der Überwachung der Einhaltung der Vorschriften dieses Gesetzes verarbeitet und genutzt werden. Eine Übermittlung, Nutzung oder Beschlagnahme dieser Daten nach anderen Rechtsvorschriften ist unzulässig.Auch wenn die Thematik an sich Platz für Diskussion läßt, zeigt es doch, dass Daten aus einem Grund erhoben werden, dann jedoch für einen grundsätzlich ganz anderen Zweck verwendet werden können, auf den man plötzlich keinen Einfluß mehr hat, denn die Daten sind schon weggegeben. Hätte man über die Umwidmung vorher Bescheid gewusst, hätte man sie ja vielleicht nicht zur Verfügung gestellt.
Ein anderes, heiß diskutiertes Thema in diesem Bereich, sind Genanalysen. Diese können helfen Krankheiten frühzeitg zu erkennen und erhöhen damit die Heilungschancen. Was aber, wenn diese Daten von Krankenkassen verwendet werden, um die Beiträge zu steuern? Anders als bei der Klassifikation bei beispielweise Rauchern oder Übergewichtigen, hat man selbst keinen Einfluss auf seine Gene und kann diese durch eine (zumutbare) Änderung seines Verhaltens auch nicht beeinflussen. Kriege ich keinen Job, weil meine Genanalyse sagt, dass ich im Durchschnitt im Jahr 5 Tage öfter krank sein werde als der Durchschnitt? Bleibt dann die soziale Gerechtigkeit auf der Strecke? Ganz sicher!Eine Umwidmung der Daten tritt auch im Falle von Datendiebstahl ein. Daten, die zum Zwecke der Strafverfolgung unter Aussetzung der Unschuldsvermutung gesammelt wurden, gehen ganz schnell nach hinten los, wenn sie von Kriminellen gestohlen oder illegal gegen Geld an diese weitergegeben werden. Man denke nur an einen vorgeblich seriösen Familienvater, dessen Handydaten-Bewegungsmuster ergibt, dass er jede Woche einmal in der Mittagspause für 30 Minuten im Rotlichtviertel unterwegs ist.
In direkterer Form gilt das, wenn Kontoinformationen in den gestohlenen Datensätzen enthalten sind. Dann werden diese Daten nicht mehr herangezogen um monatliche Abschlagszahlung, etwa für Gas und Strom, abzubuchen, dann buchen sich Kriminelle das Geld auf ihre eigenen Konten: "Verbraucherzentrale: Massenhafter Missbrauch von Bankkonten-Daten".- Je mehr Daten zu einer Person und je zentraler diese Daten gespeichert sind, desto attraktiver wird es diese Datensammlungen zu missbrauchen, für alle, nicht nur für Kriminelle. Je grösser diese Sammlungen sind, desto grösser ist der GAU, im Falle eines unberechtigten Zugriffs. Je lukrativer der Missbrauch und missbräuchliche Zugriff auf derlei Daten für Kriminelle wird, mit desto mehr Nachdruck werden sie versuchen, an derartige Daten zu gelangen.
Eine Strategie zum Schutz der Daten ist also, sie möglichst dezentral zu speichern und zu verwalten, d.h. keine zentralen Sammeldateien anzulegen.
Der sicherste Schutz der Daten ist jedoch, sie erst gar nicht zu erheben oder bereit zu stellen. Das ist ein Faktum. Sicher ist es bei manchen Vorgängen um einiges leichter, wenn die Daten existieren, aber man muss immer die Vor- und die Nachteile abwägen. Darüber kann man dann wieder herzhaft diskutieren, wenn man die Vor- und Nachteile kennt.
Zweiter Teil: Datenschutz (II) - Nimmersatte
Bye bye, sueddeutsche.de
Ich mag es nicht so sehr ausspioniert, verstatistikt, vermessen oder gar überwacht zu werden. Und wenn dann will ich wenigstens wissen, was für Daten gespeichert werden und wofür sie verwendet werden. Aus diesem Grund verwende ich in meinem Browser einen mit sehr restriktiven Voreinstellungen versehenen Cookie-Manager, einen Javascript-Blocker und ich lade meinen Seiten über einen lokal installierten squid Proxyserver, den ich mit einem Satz von ACLs ausgestattet haben (eine ständig wachsende Liste). Eine Reihe von ACLs ist für Schnüffler:
[ ... ] acl webbeacons_dom dstdomain .etracker.com acl webbeacons_dom dstdomain .etracker.de acl webbeacons_dom dstdomain .google-analytics.com acl webbeacons_dom dstdomain .ivwbox.de acl webbeacons_dom dstdomain .sitestat.com acl webbeacons_dom dstdomain stats.surfaid.ihost.com [ ... ] http_access deny webbeacons_dom
Damit weist der Proxyserver Anfragen an Domains, die dem jeweiligen Muster genügen, mit einer Fehlermeldung zurück, d.h. mein Browser kann nicht mit den Schnüfflern sprechen.
Schon seit recht langer Zeit habe ich den RSS-Feed von sueddeutsche.de abonniert. Aufgrund diverser Umstände bin ich aber seit Mitte August nicht mehr dazu gekommen ihn zu lesen, was ich heute im Schnelldurchlauf nachholen wollte, aber siehe da, es geht nicht mehr:
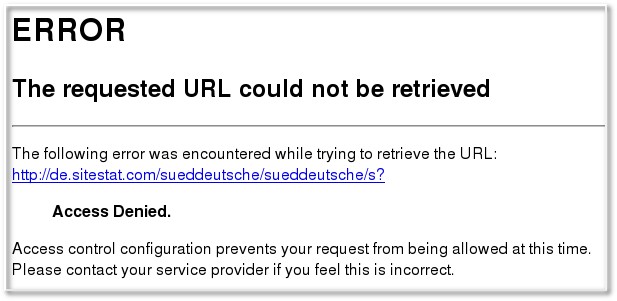
Der Grund dafür ist auch recht schnell in den Logfiles gefunden. Auch wenn die URLs im Feed noch schön brav auf eine Adresse bei sueddeutsche.de zeigen
http://rssfeed.sueddeutsche.de/c/795/f/448324/s/6d832c1/l/0Lde0Bsitestat0N0Csueddeutsche0Csueddeutsche0Cs0D onclick0Irss0Bfeed0Bmuenchen0Gns0Itype0Fclickin0Gns0Isource0Fnachrichten0Imuenchen0Gns0Iurl0Fhttp0J3a0C0C0S sueddeutsche0Bde0Cmuenchen0C4650C4928190Ctext0C/story01.htm
lösen Sie eine Weiterleitung aus nach
http://da.feedsportal.com/c/795/f/448324/s/6d832c1/l/0Lde0Bsitestat0N0Csueddeutsche0Csueddeutsche0Cs0D onclick0Irss0Bfeed0Bmuenchen0Gns0Itype0Fclickin0Gns0Isource0Fnachrichten0Imuenchen0Gns0Iurl0Fhttp0J3a0 C0C0Ssueddeutsche0Bde0Cmuenchen0C4650C4928190Ctext0C/ia1.htm
was wiederum eine Weiterleitung auslöst nach
http://de.sitestat.com/sueddeutsche/sueddeutsche/s?...
und das wird in obigen ACLs geblockt. Es läuft also sogar nicht nur über einen Schnüffler, sondern über deren zwei. Statt aber, wie andere, einen Webbug im Artikel zum Zählen zu platzieren, bekommt man von sueddeutsche.de über den Feed gar nichts, wenn man sich nicht zählen lässt.
Damit kann ich den Feed von sueddeutsche.de jetzt abbestellen. Bye bye!
Dynamic DNS selbst gemacht
Da wir mehrere Linux/Unix-Rechner im Familienumfeld hinter DSL-Zugängen stehen haben und diese betreuen, ist es ziemlich essentiell, diese auch zu finden. Der Standardansatz sind hier sicherlich dynamische DNS-Updates, vor allem, wenn dem Benutzer nicht zugemutet werden will mit der Kommandozeile zu arbeiten oder in der Routerkonfiguration zu navigieren, um die externe IP-Adresse festzustellen.
Es gibt zwar jede Menge Anbieter für dynamische DNS Services, hat man aber - wie wir - eigene Domains und macht auch den DNS Service selbst, so kann man sich den Rückgriff auf diese Anbieter sparen.
Ziemlich verwunderlich finde ich, dass die meisten Hoster, die auch Domainhosting anbieten, nicht ermöglichen, dass man
Nachfolgend eine kleine Anleitung ...
Continue reading "Dynamic DNS selbst gemacht"Es herbstelt (I)
Nachdem Frau B. ein Depribild nach dem anderen veröffentlicht und auch bei der Olsenbande herbstliche Stimmung anklingt...

Logfileauswertung - und die Security bleibt auf der Strecke
 Ich interessiere mich gerade für Webtraffic und Spiders und bastele dazu an einem "realtime Monitor", den man auf das Logfile des Webservers ansetzen kann. Passend dazu kam gestern über FriendFeed ein Link von Charleno Pires zu einem Artikel bei IBM developerWorks® mit dem Titel "Working with Web server logs" in python.
Ich interessiere mich gerade für Webtraffic und Spiders und bastele dazu an einem "realtime Monitor", den man auf das Logfile des Webservers ansetzen kann. Passend dazu kam gestern über FriendFeed ein Link von Charleno Pires zu einem Artikel bei IBM developerWorks® mit dem Titel "Working with Web server logs" in python.
Wenig erstaunlich macht der Autor Uche Ogbuji erst einmal einiges recht ähnlich, doch im zweiten Teil des Artikels nimmt er die Daten und packt sie in Webseiten zur Darstellung. Dabei macht er einen kapitalen Fehler und übernimmt alles ungeprüft. Da die Daten zu "localpath", "referrer", "user-agent" und natürlich auch zu "ident" oder "cookie" vom Client kommen, kann da ziemlich Übles drinstehen (was den Server beim Loggen auch gar nicht interessiert), wie z.B. Folgendes, was sich letzt' in einem meiner Logfiles fand:
a.b.c.d - - [25/Sep/2009:20:42:21 +0200] "HEAD / HTTP/1.1" 200 - "<script>alert(new Date());</script>" "Foxconn D910.0.3.53 FS_D910.0.2.48_DTC"
Wie man sieht, wurde hier - statt einer URI - im Referrer-Feld Javascript-Code übergeben. Übernimmt man diesen nun ungeprüft in eine Webseite mit einer Referrer-Auswertung, so wird beim Betrachten mit aktiviertem Javascript ein Popup mit der aktuellen Uhrzeit aufgehen.
Neben diesem eher sehr harmlosen Beispiel gehen damit auch andere Sachen, bis hin zu übelsten XSS-Angriffen.
Das Problem ist aber nicht nur auf Darstellung im Web/HTML beschränkt, auch mit einer reinen Textdarstellung in einer ANSI/VTxxx kompatiblen Konsole (xterm, putty, ...) lassen sich Logfile-Einträge überschreiben, indem die Darstellung mit entsprechenden Steuersequenzen manipuliert wird. Manche Terminal-Emulationen erlauben sogar die Modifikation der Cut-Buffer und/oder Funktionstasten, andere haben Funktionen für Record und Playback für Macros.
Generell gilt immer:
Nichts, was das Internet anliefert, ist vertrauenswürdig.
Nominum startet Skye cloud DNS service
Nominum, eine private Firma, in der sich so illustre Namen wie Paul Mockapetris, Paul Vixie, Ted Hardie oder Stephen Stuart zusammenfinden, wurde gegründet um BIND9 und DHCP3 für das Internet Systems Consortium (ISC; damals noch Internet Software Consortium) zu entwickeln. Mittlerweile haben sie eine komplett eigenständige Lösung für DNS entwickelt.
Vor einiger Zeit gab es nun eine Pressemeldung über den Launch von Skye und dazu ein Interview auf ZDNet UK mit Jon Shalowitz von Nomium unter dem Titel "Why open-source DNS is 'internet's dirty little secret'".
Einerseits ist es ganz amüsant zu lesen, was Jon Shalowitz für einen Blödsinn über Freeware/Open Source Software erzählt und sich damit zum Affen macht, indem er mit der Mär von der unsicheren Open Source Software argumentiert. Im Gegensatz zur viel älteren Freeware Lösung djbdns von Dan J. Bernstein oder anderen OSS Lösungen wie MaraDNS oder powerDNS, waren die Nominum DNS Server vom UDP Port Prediction [2] Angriff und damit verbundenem Cache Poisoning durchaus betroffen.
Andererseits erzählt er über wirklich bedenkliche Ansätze, die Nominum mit Skye verfolgt:
If you use as an example NTT, one of our customers in Asia — we can quickly detect a worm outbreak or a botnet outbreak, because of what we see in the DNS. Then we can use that information to shut down a lot of those communication lines that that command centre, that botnet, may use. We can apply that worldwide across our entire installed base.
Nominum macht die feuchten Träume aller Internet-Zensoren wahr:
"Auf Knopfdruck knipsen wir beliebige Domains aus"
Aber das ist natürlich eine schlechtere PR-Aussage als "wir schützen euch alle" (ob ihr wollt oder nicht).
DNS, Mail, DNSxLists und blutige Amateure
Letzt' habe ich geholfen einen hoffnungslos mit Spam-Angriffen überrannten Mailserver wieder einigermassen produktiv zu bekommen.
spamassassin und clamav mögen ja nette Tools sein und auch einiges an Spam und Viren oder Malware im allgemeinen wegsortieren, ist aber der Rechner an der Grenze seiner Leistungsfähigkeit angekommen, muß man (sollte man eigentlich immer) viel früher anfangen diesen Müll abzuweisen. Dies hat zudem den großen Vorteil, dass man Backscatter vermeidet, weil die Spam-Zombies keine NDNs generieren.
Reputation ist alles
Kein Name, keine Reputation
Einer der ersten Schritte, den ich diesbezüglich immer gehe ist, dass ich alle Verbindungen sofort abbrechen lasse, wenn sie von Rechnern kommen, die keinen Eintrag im reverse DNS haben.
Ein anständiger und von verantwortungsvollen Admins verwalteter Mailserver wird einen korrekten Eintrag im DNS haben. Wenn - aus welchen Gründen auch immer - das nicht so ist, dann ist das nicht der Fehler der Empfänger, sondern der der Admins des Versenders und nicht die Empfänger müssen dafür geradestehen und trotzdem versuchen es irgendwie noch hinzubiegen. Dies gilt umso mehr, wenn sie dabei in Kauf nehmen müssten, dass sie auch von 100 Millionen Zombies Mail annehmen, nur weil die Admins der Versender es nicht raffen.
Das hat schon mal 30-50% der Angreifer ausgeschaltet, einen Großteil der Last vom Rechner genommen und bringt connection slots, weil diese Verbindungen nicht mehrere Sekunden oder gar Minuten eine SMTP-Verbindung blockieren.
Verbinden Sie sich mit Ihrem guten Namen
Nachdem alle Verbindungen mit namenlosen Hosts unterbunden sind, sortiert man 08/15 Namen aus (sprich Zombies hinter DSL/broadband, für die der ISP einen Namen eingetragen hat).
Da im allgemeinen der ISP einen Überblick darüber hat wie er die ihm zugeteilten Adressen/Netzbereiche verwendet, ist die Klassifizierung über Namen prinzipiell einer Klassifizierung über reine IP-Adreßbereiche vorzuziehen. Manchmal ist dies auch recht angenehm und schnell gemacht, wenn der ISP bei der Namensgebung mitspielt und eine entsprechende Hierarchie verwendet:
.dynamic.163data.com.cn
.broadband.corbina.ru
.dynamic.jazztel.es
.dsl-dynamic.vsi.ru
.dial.nortenet.pt
.pppoe.avangard-dsl.ru
Hier haben die Admins verstanden, wie DNS funktioniert: hierarchisch und von rechts nach links. Derartige Domains kann man leicht sowohl in lokalen Konfigurationen als auch in DNSBLs konfigurieren und das matching geht schnell und unkompliziert. Natürlich will man nicht nur Blacklists, sondern (z.B. im Falle von greylisting) auch Whitelists haben, und auch hier gibt es positive Beispiele:
.mail.uk.clara.net
.mail.kks.yahoo.co.jp
.mail.interoute.net
.mail.uu.net
.mail.gandi.net
Auf diese Art und Weise kann man mit einem einzelnen Eintrag eine ganze Reihe von Mailservern freischalten. Ja, ACLs nach Namen sind unsicher, es sei denn man verwendet ein "paranoid" setting.
Die "blutigen Amateure"
Neben obigen positiven Beispielen, gibt es auch jede Menge Beispiel dafür, dass offensichtlich die Leute nicht kapiert haben, wie DNS funktioniert. Interessanterweise sind auch jede Menge "Checker-Firmen" darunter, von denen man das eher nicht erwartet. Hier einige Beispiele:
mail-yw0-f147.google.com
mail-bw0-f206.google.com
outbound-mail-49.bluehost.com
mail22.infracom.nl
static-nnn-nnn-nnn-nnn.netcologne.de
ip-95-223-70-58.unitymediagroup.de
ppp-77-234-231-97.dsidata.sk
rev.193.226.199.13.euroweb.hu
host219-46-dynamic.21-87-r.retail.telecomitalia.it
Die haben es alle nicht kapiert. Entweder es gibt gar keine Hierarchie oder sie drehen innerhalb ihrer Domain die Hierarchie um von links nach rechts. Zur Verdeutlichung wollen wir einmal zwei Namen gegenüberstellen:
static-<a>-<b>-<c>-<d>.example.com
sys-<n>.example.com
Beides sind Namen von Rechnern, die Verbindungen per SMTP aufbauen. Das eine ist ein Kundensystem, das Spam verteilt, das andere ein (interner) Mailserver.
An dieser Stelle sollte ich wohl explizit erwähnen, dass dies exemplarisch ist und das erste von hunderten von Beispielen, die ich gefunden habe. Es geht nicht darum irgendwen im speziellen zu "bashen".
Der gemeinsame Domainanteil dieser Hosts ist .example.com. Damit wird das Problem deutlich. Will man nicht mit kompliziertem pattern matching arbeiten, sondern einfache RTL-Hierarchien verwenden, hat man hier verloren. Dies gilt im speziellen auch für DNS{B,W}Lists.
Und bevor jetzt jemand kommt und sagt: "Ich will aber lieber mail22 tippen als h22.mail!" - dann tragt euch doch einen CNAME ein oder verwendet Host und Hostname für die ssh.