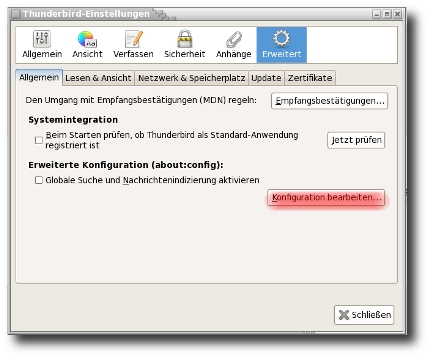
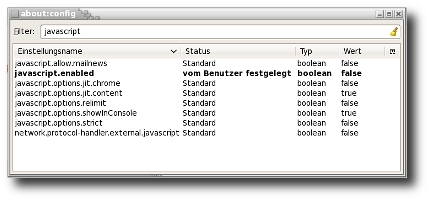
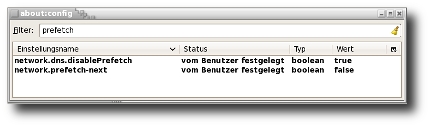
"Datenschutz" ist wieder in aller Munde. Ein böser "Hacker" hat einmal mehr Daten von StudiVZ "geklaut". Na ja, nicht wirklich, er hat nur automatisiert die Daten der Benutzer abgegriffen, die diese bereit waren ihm, einem Mitglied von StudiVZ, zu geben. Getan hat er das mit einem sogenannten Crawler, also einem Programm, das sich von Webseite zu Webseite hangelt, so wie zB. Suchmaschinen das auch tun.
Es gibt eine ganze Reihe von sogenannten Personensuchmaschinen, die machen nichts anderes. Sie haben einen Crawler, der Webseiten abruft und sie haben ein data mining Programm, das diese Seiten analysiert, versucht Personeninformationen zu finden und zu extrahieren und danach werden diese Informationen - mehr oder weniger intelligent - gruppiert. Dies passiert mit den zusammengetragenen Benutzerdaten von tausenden von Webseiten. Manche dieser Suchmaschinen bieten ihre Daten öffentlich an (yasni.de, 123people, myONID.de, wink.com, spock.com), andere verkaufen diese Information für viel Geld an Personalabteilungen, die so ihre Bewerber abklopfen.
"Normale" Suchmaschinen können das auch ... vielleicht sogar noch besser. Ein Beispiel dafür ist der Social Circle von Google. Dadurch, dass sich Menschen auf verschiedenen Plattformen (XING, Twitter, Facebook, FriendFeed usw.) vernetzen und diese Informationen teilweise öffentlich sind (Friends, Followers), können Suchmaschinen diese Beziehungsinformationen auswerten, Profile erstellen und Verknüpfungsgeflechte generieren. Anhand weiterer Daten (semantisch gekennzeichnete Verweise auf Homepage, Blog, XYZ-Profil) lassen sich derartige plattformübergreifenden Profile sehr gut befüllen und so ist es dann auch nicht verwunderlich, dass, wenn ich bei Google angemeldet bin und eine Suchanfrage mache, mir Google ganz nebenbei mitteilt, dass einer meiner "sozialen Kontakte" gerade einen neuen Artikel in seinem Blog veröffentlicht hat.
Dieses data mining ist nicht nur auf Personendaten beschränkt. Manche Firmen haben sich auf Urheberrechtsverletzungen spezialisiert (PicScout), andere überwachen Markennamen (Brandwatch). Allen gemein ist, sie scannen permanent das gesamte Internet (oder versuchen es zumindest) und generieren und speichern verschiedene Arten von Profilen.
Social Networks
Der Begriff "Social Networks", wie er im Deutschen gemeinhin verwendet wird, ist falsch. "Social Networking Sites" trifft es schon viel besser und macht den organisatorischen Bezug zu den Mailboxsystemen früherer Zeiten deutlich.
Bei einer Social Networking Site handelt es sich um ein mehr oder eher weniger abgeschlossenes System.
- mehr, weil man für manches Mitglied sein muß.
- weniger, weil die Geschlossenheit keine wirkliche ist, sondern primär der Authentifizierung der Benutzer und der Generierung neuer Mitglieder dient. Jeder kann Mitglied werden, somit ist die Geschlossenheit nur formal.
Die Vertraulichkeits-Voreinstellungen solcher Systeme sind natürlich immer systemfreundlich: das ganze Internet darf nicht, alle Benutzer des Systems dürfen schon. Klar, soll ja neue Mitglieder anlocken und intern so viel wie möglich bieten. Dass der vorgegaukelte Unterschied zwischen "alle im System" und "das ganze Internet" nur formal existiert (jeder kann Mitglied werden) und gar keinen wirklichen Sinn macht, ist ein Mißverständnis, das sich für viele Teilnehmer nicht oder nur sehr spät (zu spät?) auflöst. Die Voreinstellung sollte immer so eng wie möglich sein, damit der Benutzer bewusst Rechte einräumen muß, widerspricht so aber dem Vernetzungsgedanken.
Zudem sollten solche Systeme vom Benutzer frei konfigurierbare Zugriffsbeschränkungen implementieren. Daran scheitern schon sehr viele, die meist nur drei oder vier vordefinierte Gruppen anbieten. Ein weiteres Manko ist oft die Granularität zur Vergabe der Rechte. So kann man ein Bilderalbum (thematische Gruppierung von Bildern) zwar einer Rechtegruppe zuordnen, nicht aber die einzelnen Bilder darin (nocheinmal gesondert).
Warum man das will? Beispiel: Fete. Alle Bilder des Albums "Fete" sollen für Mitglieder der Gruppe "Fete" sichtbar sein, nicht jedoch das Bild "Joe peinlich", das nur für "Joe" sichtbar sein soll.
Ein weiteres Problem tritt mit obigem Beispiel ebenfalls zutage: alle müssen Mitglieder dieses Systems sein, da sonst das System sie nicht identifizieren und authentifizieren kann. Ein "Ich habe die Bilder der Fete unter dem URL ... abgelegt. Benutzername/Passwort zum Anschauen sind ..." funktioniert nicht. Fetenteilnehmer, die nicht im System registriert sind können die Bilder nicht ansehen.
Dies führt direkt zu einem weiteren Problem dieser Systeme und der Vertraulichkeit von Daten.
Vertrauen
Daten sind immer nur so vertraulich, wie man der Person/Organisation vertrauen kann, an die man sie weitergibt.
Was nützt es Daten in einem geschlossenen und geschütztem System zu haben, wenn die Personen, die Zugriff darauf haben, (absichtlich oder nicht absichtlich) nicht vertrauenswürdig sind.
- bei "absichtlich nicht vertrauenswürdig" sollte klar sein, was es bedeutet.
- bei "unabsichtlich nicht vertrauenswürdig" besteht vielleicht Erklärungsbedarf.
Betrachtet man obiges Besipiel der Fotos des Festes wird auffallen, dass es ziemlich unwahrscheinlich ist, dass alle Teilnehmer der Fete auch Mitglieder des Systems sind, in welchem die Fotos veröffentlicht wurden. Dies führt dann zu dem Fall, in dem ein Mitglied mit Zugriff darauf diese Fotos aus dem System "entfernt" und einem Fetenteilnehmer, der kein Mitglied ist, zB. per E-Mail zuschickt. Dem Mitglied wird in diesem Moment sicher nicht klar, dass er einen Vertrauensmißbrauch begeht, denn "die Fotos waren doch für die Teilnehmer der Fete".
Diese Annahme ist aber falsch, denn es war für "die Teilnehmer der Fete, die Mitglieder der Gruppe "Fete" des Benutzers des Systems sind, der die Bilder eingebracht hat". Eventuell hätte dieser ja das eine oder andere Bild nicht eingestellt, wenn die externe Person ebenfalls Mitglied gewesen wäre oder er hätte die Zugriffsberechtigungen (einiger Bilder) anders gesetzt.
Durch die Entnahme der Bilder aus dem Schutz des Systems wurde die Vertraulichkeit der Daten ausgehebelt.
Ein weitergehender Verlust der Vertraulichkeit der Daten erfolgt in dem Moment, in dem die externe Person diese per E-Mail erhaltenen Bilder an eigene Freunde weiterschickt, die vielleicht gar nicht auf der Fete waren: "das sind Bilder der tollen Fete, auf der ich am Wochenende war". Der Totalverlust tritt ein, wenn die Bilder ungeschützt in zB. einer Foto-Community veröffentlicht werden.
Kopieren verboten
Mit dem Slogan "Kopieren verboten" hat eine Firma auf einem Sicherheitskongress vor ein paar Jahren ihr Produkt angepriesen und wollte damit "die Vertraulichkeit Ihrer Dokumente schützen". Sie haben damals meinen Kommentar dazu "was ich sehe gehört mir" nicht verstanden. Das Produkt hat auf Betriebssystembasis verhindert, dass man zB. PDF-Dokumente kopieren kann und sollte damit eine Vertraulichkeit des Dokuments erreichen. Das ist aber zu kurz gedacht. Niemand hat verhindert, dass
- Screenshots von jeder Seite des Dokuments gemacht werden können
- das Dokument seitenweise vom Bildschirm abfotografiert werden kann
- das Dokument per Hand auf Papier übertragen werden kann
- und nicht zuletzt: der Inhalt des Dokuments mündlich weitergegeben werden kann
What has been seen cannot be unseen.
Ein weiteres Beispiel dafür, wie schnell man die Kontrolle über "vertrauliche Daten" verlieren kann, zeigt sich beim Sexting. Damit wird das "sex texting" erotischer Fotos vom eigenen Körper bezeichnet, aufgenommen mit der Fotofunktion des Mobiltelefons und anschließend per MMS direkt verschickt.
Mag das eine Laune gewesen, als anregende Unterstützung für Cyber-/Telefonsex gedacht oder auch nur ein Vertrauensbeweis gewesen sein, kann dies schnell aus dem Ruder laufen, wenn der Empfänger diese Bilder im (meist gleichgeschlechtlichen) Freundeskreis quasi als Trophäe präsentiert oder wenn nach dem Ende einer Beziehung der/die Verlassene glaubt sich rächen zu müssen, indem er/sie die Bilder veröffentlicht.
Tolle neue Social Networks
Nach all der Kritik an den bestehenden Social Networks hat vor allem diaspora* in den letzten Tagen den vollen Medienhype erlebt. Es ist nicht das einzige Projekt, das mit dem Anspruch an den Start geht mehr Datenschutz zu gewährleisten. Eine Liste solcher Projekte wird von der Free Software Foundation (FSF) als Gegenüberstellung verwaltet.
Ein paar der Systeme habe ich mir angeschaut. Ich brainstorme selbst seit etwa 3 Jahren an so einem System, denke also ich kann mir hierzu einen Kommentar erlauben  . All diese Systeme verfehlen ihre Ziele. Es ist nicht die Herausforderung ein paar hundert oder tausend Zeilen in PHP runterzuhacken und man hat was Tolles.
. All diese Systeme verfehlen ihre Ziele. Es ist nicht die Herausforderung ein paar hundert oder tausend Zeilen in PHP runterzuhacken und man hat was Tolles.
Die Herausforderung ist ein prinzipielles System zu entwerfen
- das verteilt ist (gib' nicht einem Anbieter alle Deine Daten)
- das trotz der Verteilung auch bei Millionen von Benutzern noch skaliert
- das Sicherheit in Form von Identifizierung und Authentifizierung enthält ("signed messages")
- das ein Reputationssystem (ala "web of trust") integriert
- das eine "Schaltzentrale" bietet, auf die man von überall her (steuernd) zugreifen kann und alle Funktionalität, die man haben will, integrieren kann (soetwas wie IMAP4 für E-Mails, das aber E-Mails, Microblogging, Bookmarks, Chat, RSS/ATOM Feeds, Blogs, Bilderalben und und und ... integriert; raindrop aus den Mozilla Labs ist schon einmal ein Stück in die richtige Richtung)
- das problemlos erweiterbar und integrierbar ist
- das plattformunabhängig ist
So ein verteiltes System muß also primär Schemata, Protokolle und Abläufe definieren, so dass die verschiedenen Knoten sauber und effizient interagieren können. Dies ist die Herausforderung - danach den Code (egal in welcher Sprache oder welchem Framework) runterzuhacken ist es nicht. Sicher kann man dazu auf bereits bestehende Dinge zurückgreifen, wie OpenID, OAuth, pubsub, ... integrieren muß man es trotzdem sauber und vieles von Grund auf neu machen.
Eingangs beschriebene Probleme mit der Vertraulichkeit oder dem Schutz der Daten werden aber auch diese Systeme alle nicht lösen, weil diese Probleme weder systemimmanent sind noch programmatisch gelöst werden können.
So, we're doomed
You can't take something off the Internet, that's like trying to take pee out of a swimming pool.
Once it's in there, it's in there.
-- NewsRadio clip, episode 2x17 "Physical Graffiti" [via YouTube]
Nein, bei weitem nicht!
So wie vor zehn oder zwanzig Jahren die wenigsten von uns damals darüber nachgedacht haben dürften, dass Artikel, die sie im USENET veröffentlicht haben und die regelmässig auf den lokalen Newsservern expired und damit veschwunden waren, plötzlich wieder auftauchen und durchsuchbar sind, so waren und sind viele im Moment noch etwas leichtsinnig, was ihren digitalen Footprint angeht. Da sowohl Soziale Netzwerke als auch für viele das Internet und nicht nur das Konsumieren in Form von Surfen, sondern gerade auch das Publizieren Neuland ist, ist dies auch keineswegs verwunderlich.
Das sind Schäden, die nicht wieder gutzumachen sind, aber solange wir alle aus diesen Schäden lernen und ein entsprechendes Bewusstsein entsteht, das anderen Neulingen hilft, diese Fehler erst gar nicht zu begehen, denke ich, ist nicht alles verloren.
Man muß sich jedoch immer vor Augen halten:
Das Internet vergisst nichts!
... und Aussagen wie "The photograph has now been removed from the internet" sind und bleiben nichts als fromme Wünsche von Leuten ohne Realitätsbewusstsein.
 Das "Widget" ist natürlich wieder eines dieser unsäglichen Bilder, die man von der Site einbindet - zumindest kein Javascript.
Das "Widget" ist natürlich wieder eines dieser unsäglichen Bilder, die man von der Site einbindet - zumindest kein Javascript.
 Das offizielle
Das offizielle 
 Am 27. Januar 2010 hat
Am 27. Januar 2010 hat  Meine E-Mails lese ich im
Meine E-Mails lese ich im